02 / WHO I AM · 오늘의 순서
현실 제약 안에서 작동·검증한 AI를 만드는 사람.
12년 — 미사일·환자·엣지·영상, 전부 ‘제약 속 작동·검증’. 오늘 이 4 케이스로 보여드립니다.
CASE 01 · 의료
실시간 영상 AI 제품화
ENAD — 200+ 병원 실배포 · 실시간
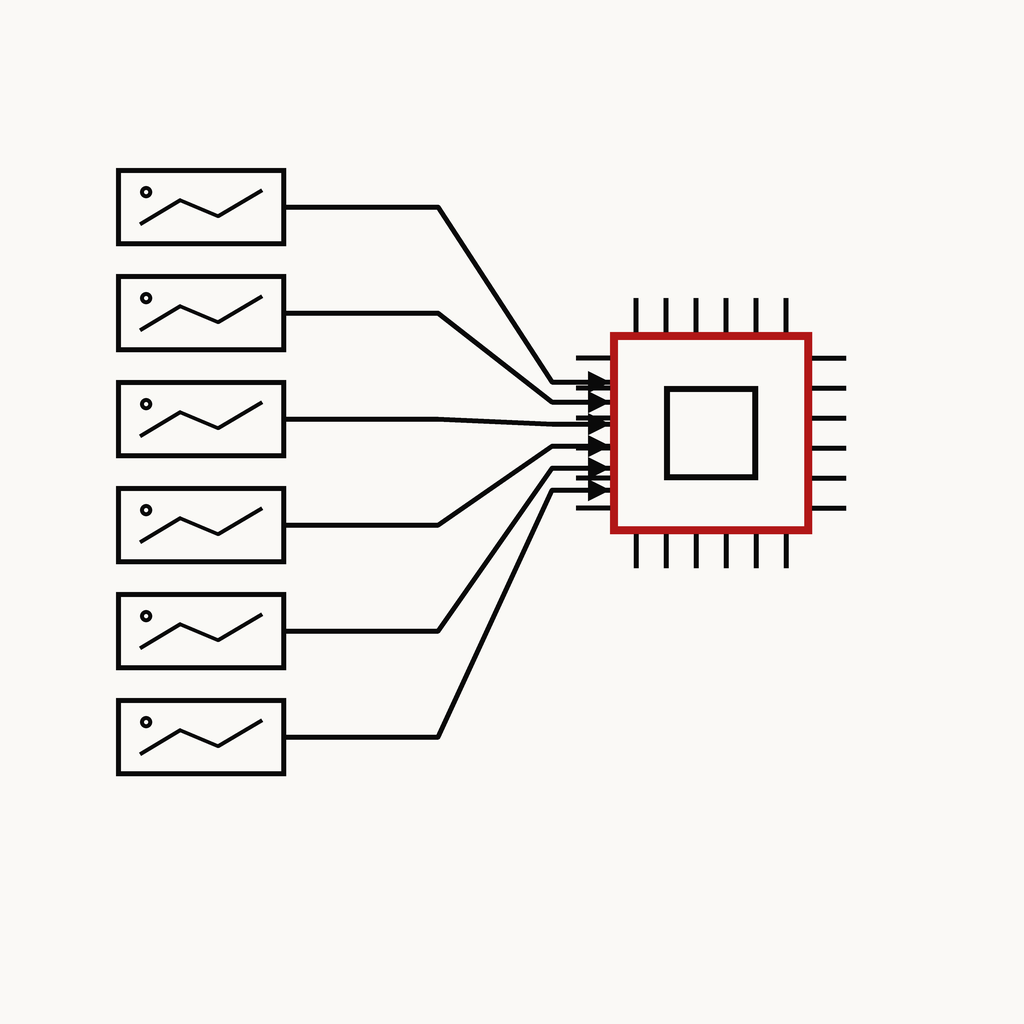
CASE 02 · 엣지
6채널 온디바이스 추론
Jetson Xavier — 서버 없이 실시간
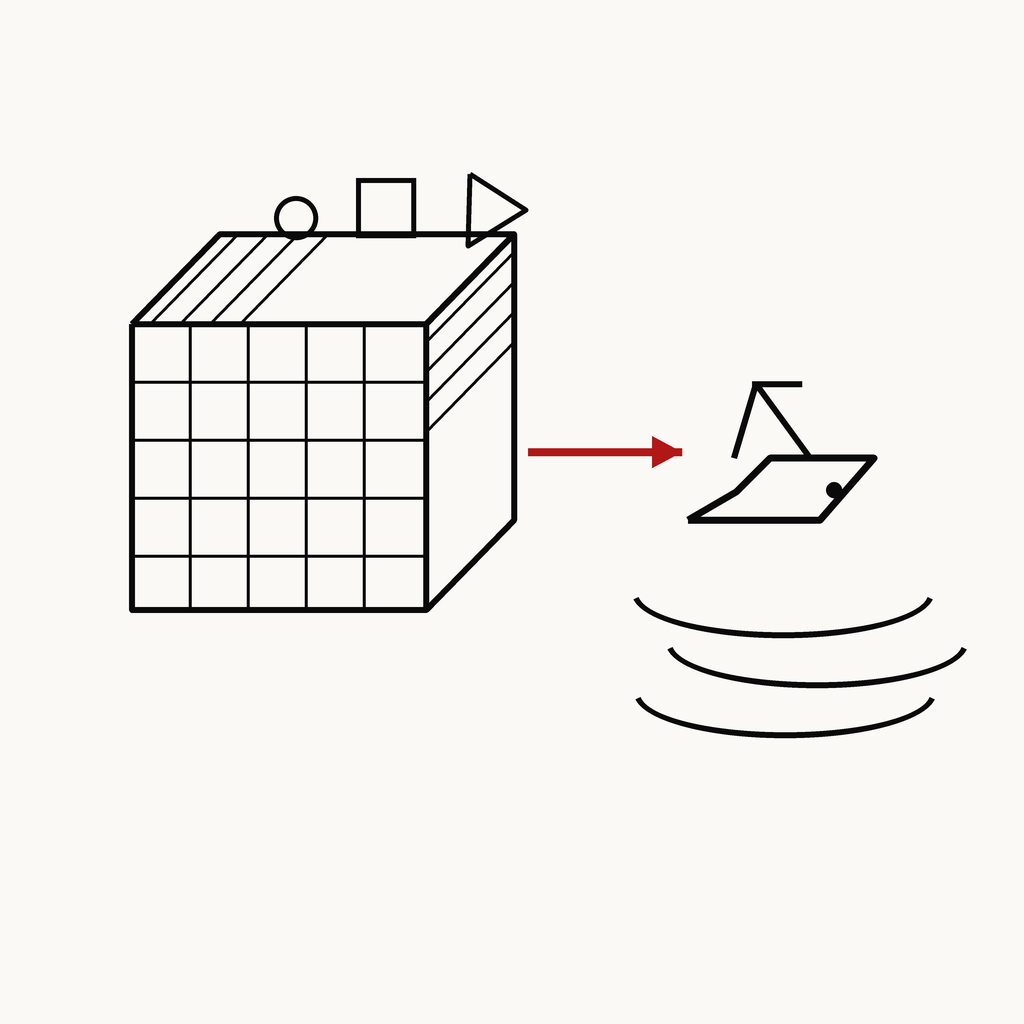
CASE 03 · 자율
시뮬레이션 · USV 자율
시뮬레이터 객체생성 — sim→real
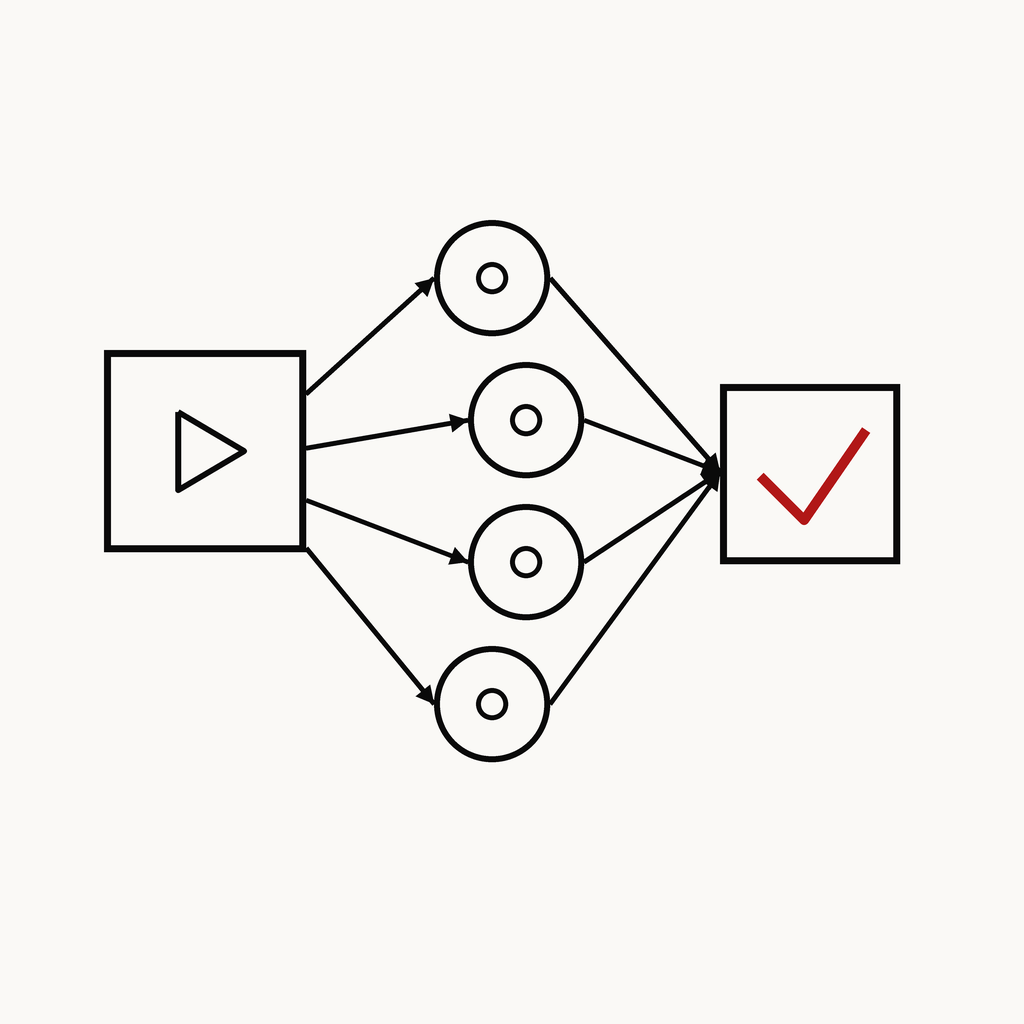
CASE 04 · 에이전트
멀티모달 VideoAgent
5-VLM 앙상블 — KRAFTON 해커톤
발표 순서 — 위 4 케이스 → 기록 → 왜 나 → 기여(KRAFTON) → 마무리. 부록(논문 8 · 특허 10)은 질문 시 펼침.
- 4case studies
- 8publications
- 7+3patents 등록·출원
- 21 win · 1 finalist
05 / CASE 01 — ENAD: 현장 제품화 & 글로벌
5가지를 하나씩 풀어, 현장에서 진짜 쓰이는 제품으로 — 그리고 글로벌.
현장 변수를 분해해 하나씩 해결하고, 병원별 환경을 반영한 현장 벤치마크 셋으로 검증했습니다. → 현장 벤치마크는 KRAFTON Orak 같은 에이전트 평가의 원형.
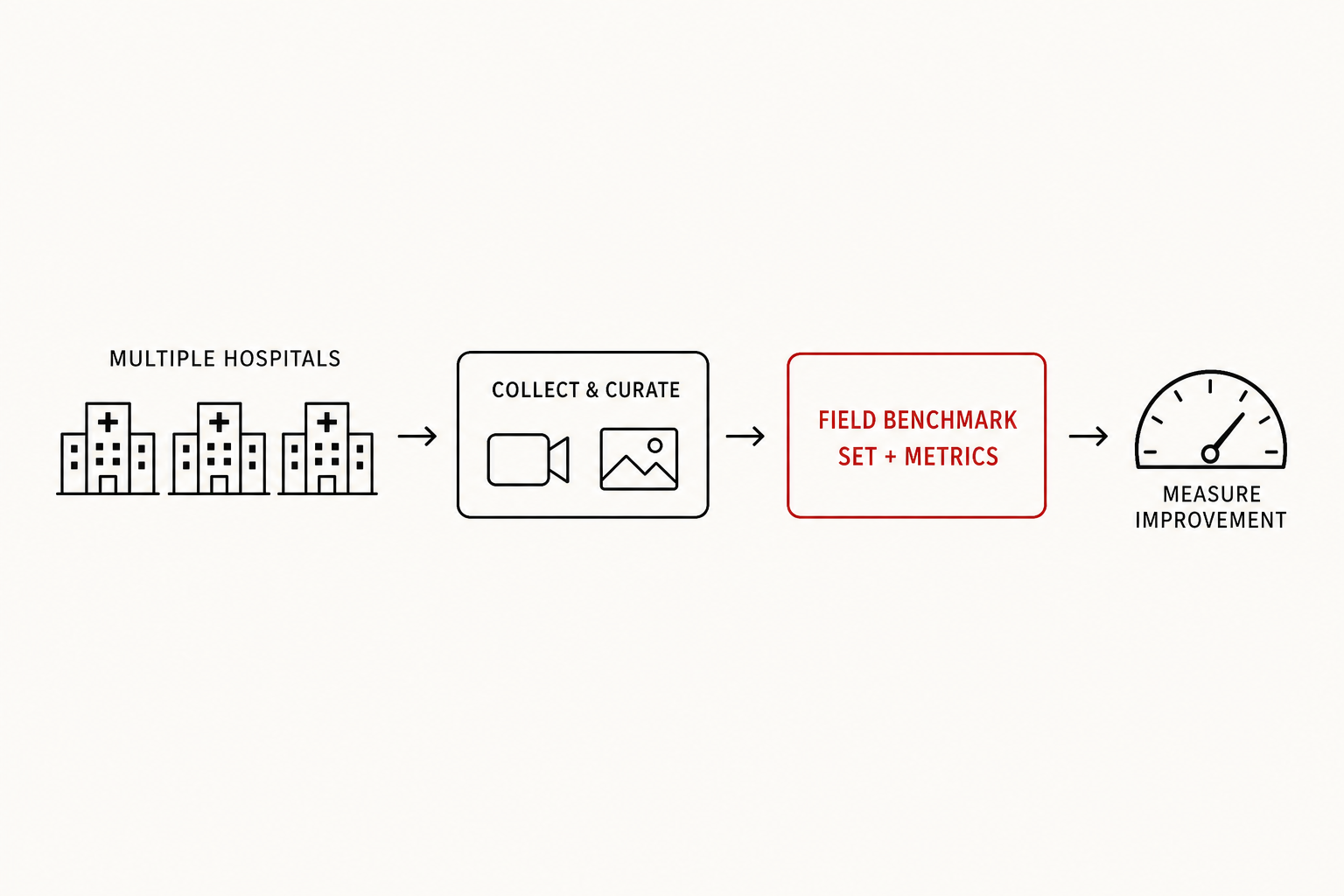
- 5현장 변수 해결
- Benchmarkfield set + metrics
- 200+병원 (제품)
- Global해외 확장
06 / CASE 01 — ENAD REAL-TIME OPTIMIZATION
검출·분류를 동시에 돌리면서, 일반 PC 한 대로 60fps를 지켜야 했습니다.
ENAD는 기존 내시경 장비에 그대로 연결돼야 했고, 실시간 60fps를 유지해야 했으며, 큰 워크스테이션을 둘 수 없었습니다. → 일반 PC 60fps = Smart Zoi 온디바이스 서빙과 같은 제약.
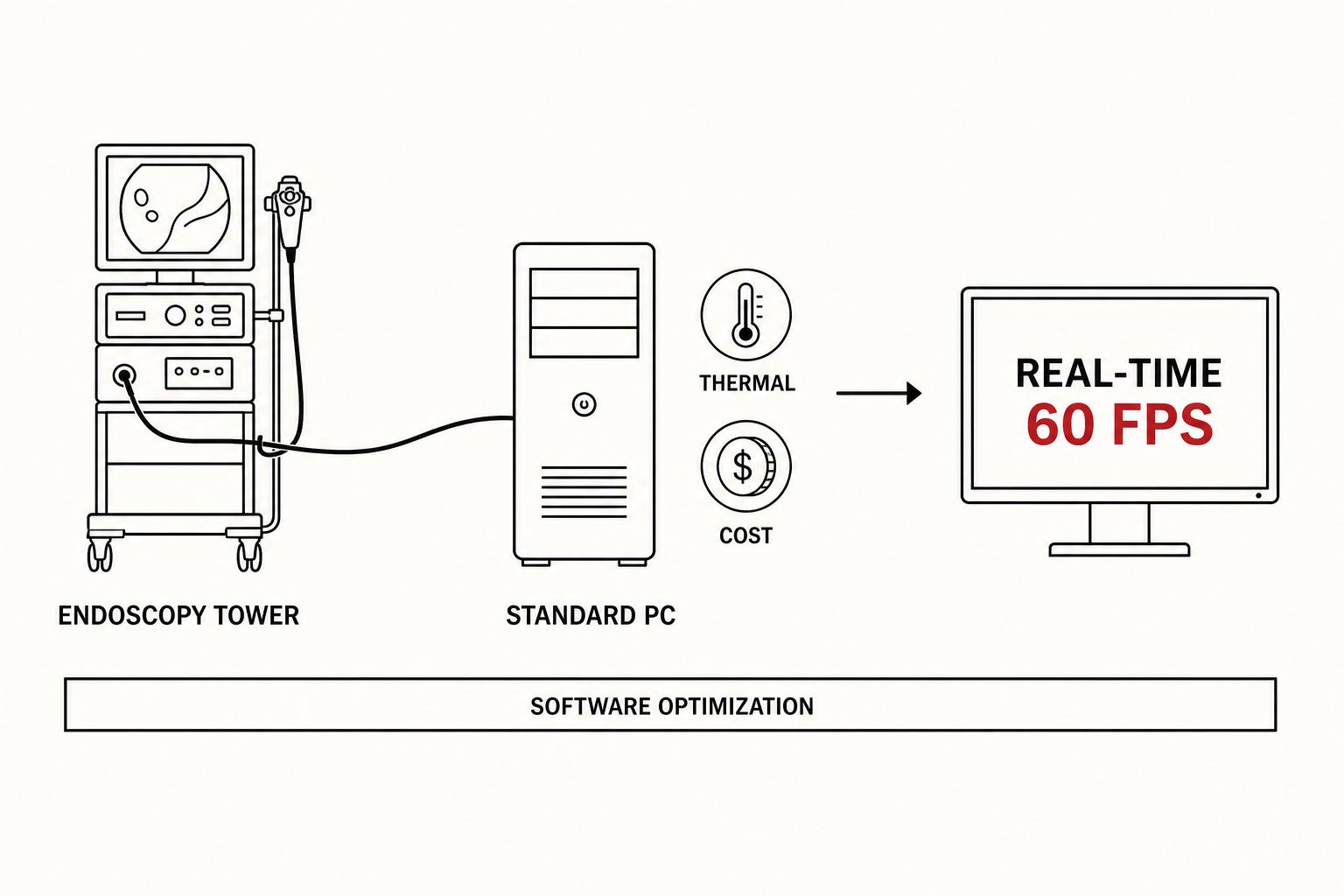
- 60 fpsreal-time, no drop
- Standard PCno big workstation
- Thermalheat + power budget
- Multi-vendorOlympus·Fujifilm·Pentax 주요 기종
07 / CASE 02 — REAL-TIME EDGE VISION (Hanwha Systems)
서버도 클라우드도 없이, 엣지 기기 한 대에서 6채널을 실시간으로 돌려야 했습니다.
클라우드 없이 기기 안(온디바이스)에서 6채널을 실시간 처리 — 서버도 여유 지연도 없는 제약에서. → 온디바이스 멀티스트림 예산 = CPC 온디바이스 추론과 같은 결.
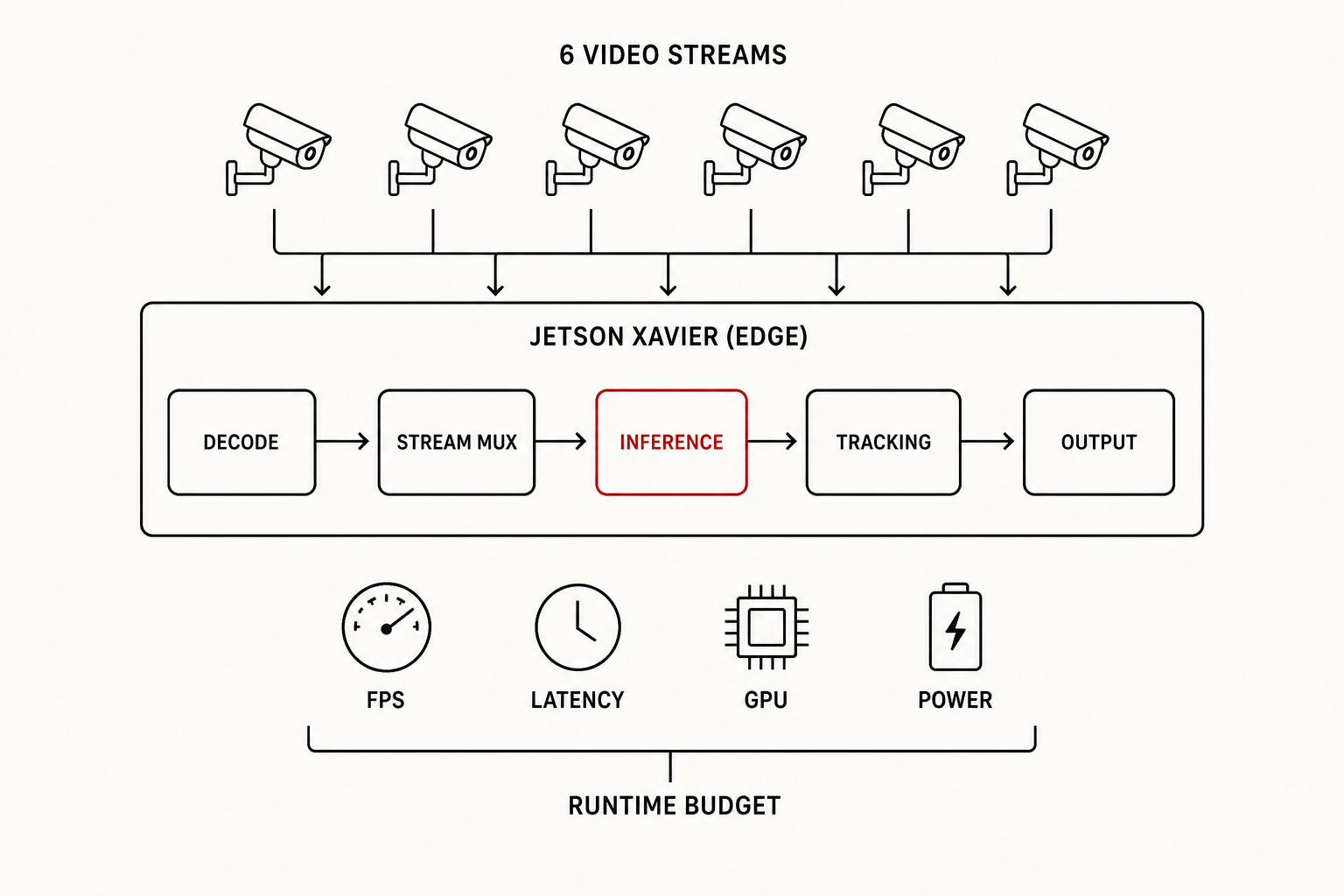
- 6chmulti-stream input
- DeepStreamobject detection pipeline
- Jetson Xavier512-core Volta · 32 TOPS · ~30W
- BudgetFPS · latency · GPU · power
10 / CASE 04 — VIDEOAGENT v3 · 왜 이렇게 만들었나 (2/2)
운영 제약(15분·토큰)이 설계를 정했습니다 — 핵심 결정 3가지.
단일 모델·단일 호출로는 약했습니다. 리포트로 검증된 3가지 결정으로 정확도를 끌어올렸습니다.
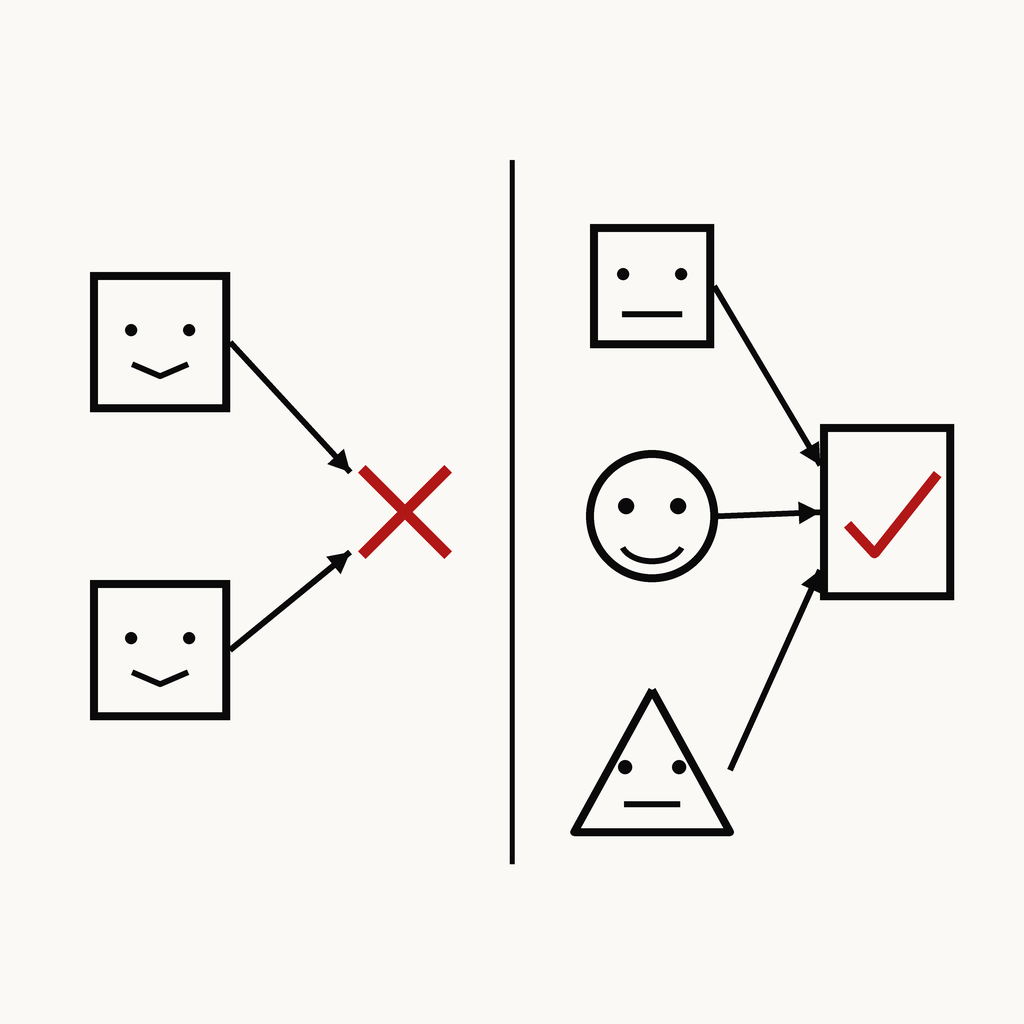
① 모델 다양성
같은 모델 = 같은 실수
→ 서로 다른 GPT·Gemini·Claude 3 패밀리로 (상관 오류 회피)
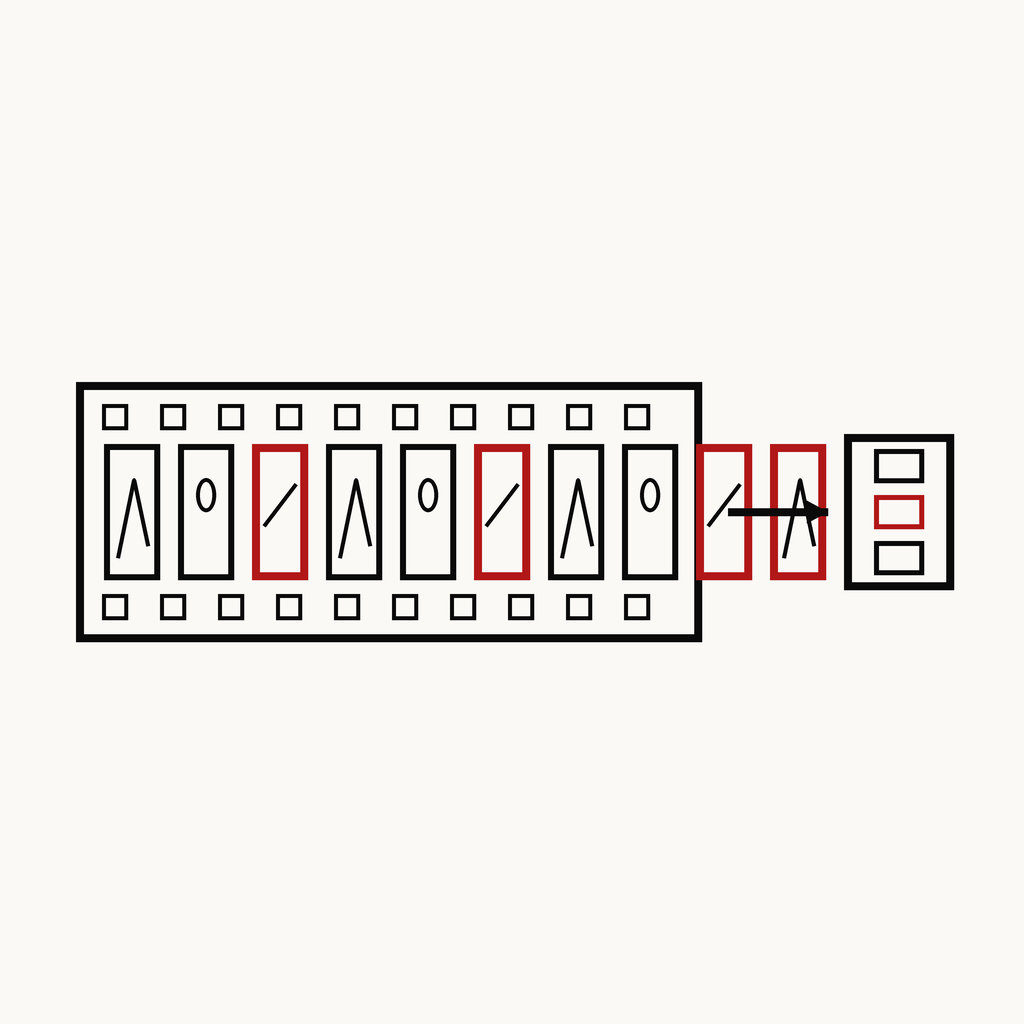
② 적응형 프레임
프레임 과다 → 빈 답
→ 질문 유형별로 꼭 필요한 프레임만 (토큰 예산 절약)
③ 5-way 투표
5개 답 → 1개 선택
→ 과반·우선순위로 (GPT합의→Claude합의→fallback)
왜 다양성이 결정적이었나 — 26지선다에선 단일 모델이 90%대 → ~50%로 무너집니다. (전부 KRAFTON 해커톤 리포트로 기록·검증)
- 3families · 5 models
- 9question types
- Vote5-way priority
- Report리포트로 검증
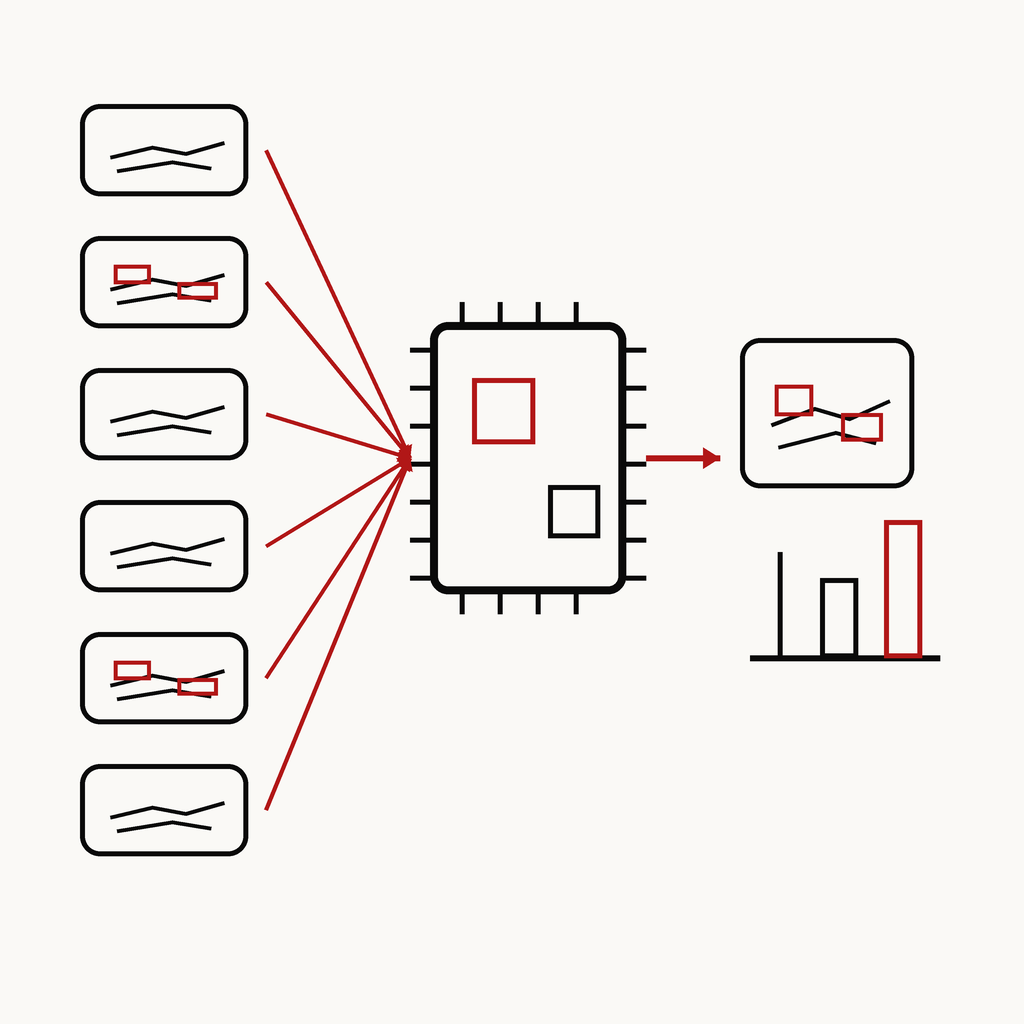
15 / APPENDIX A — PUBLICATIONS (8)
논문 8편 — 대부분 실시간 인지·판단 AI, 기반은 신호처리.
국제 저널 6 + 국내 학회 2 — 의료 영상 실시간 검출이 핵심, 신호처리(석사)가 토대. 각 카드: 무엇을 했나 · 왜 KRAFTON과 연결되나.
실시간 영상
Colorectal Polyp Optical Diagnosis
Gut and Liver · 2026
① 실시간 폴립 광학진단 AI를 임상에 통합
② 실시간 영상 인지 = 게임 화면 인지의 원형
오탐 해결
Specular-Reflection Data Augmentation
Biomedical Eng. Letters · 2026
① 빛 반사 재현 증강으로 오탐↓
② 노이즈 강건성 = 에이전트 인지 견고성
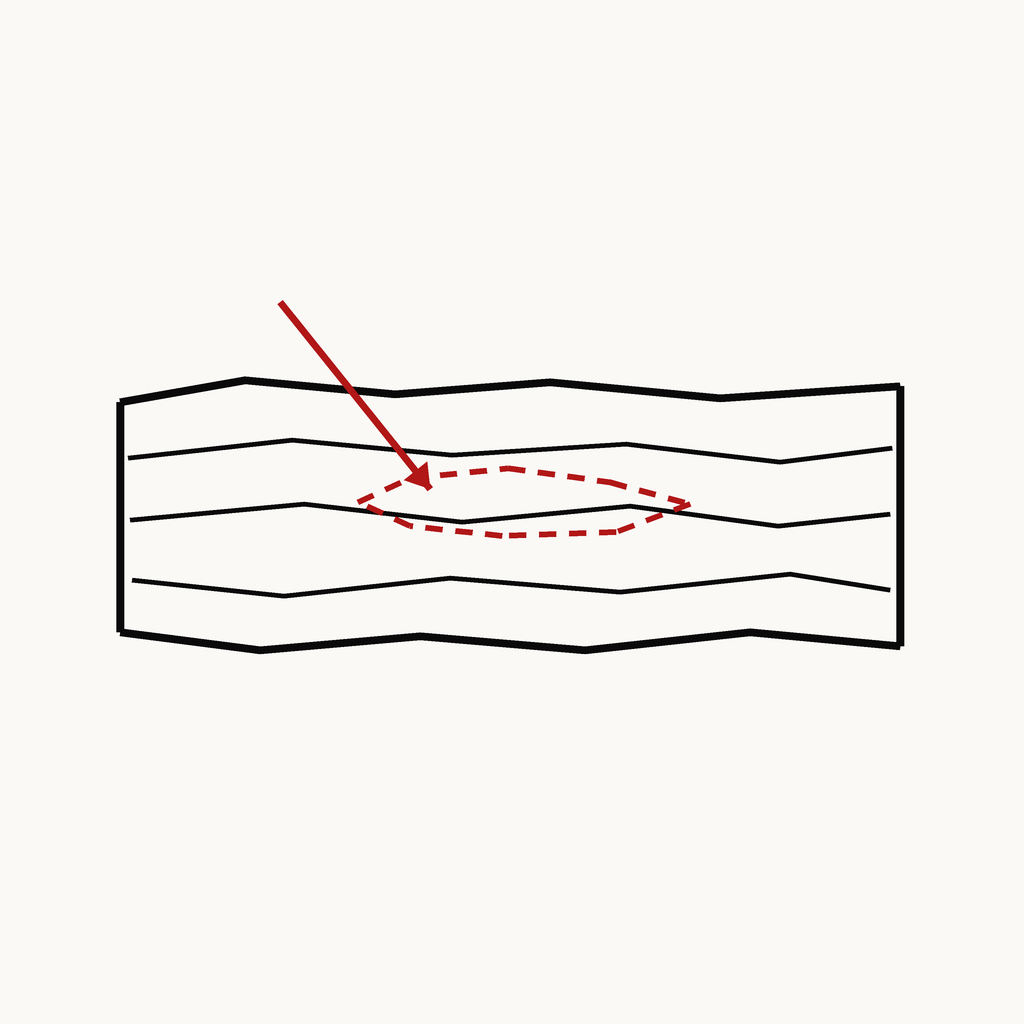
미탐 해결
Borrmann Type 4 Gastric Cancer Detection
Cancer · 2025
① 퍼지는 침윤형 위암(미탐) 검출
② 어려운 edge-case 검출 = 평가·안전
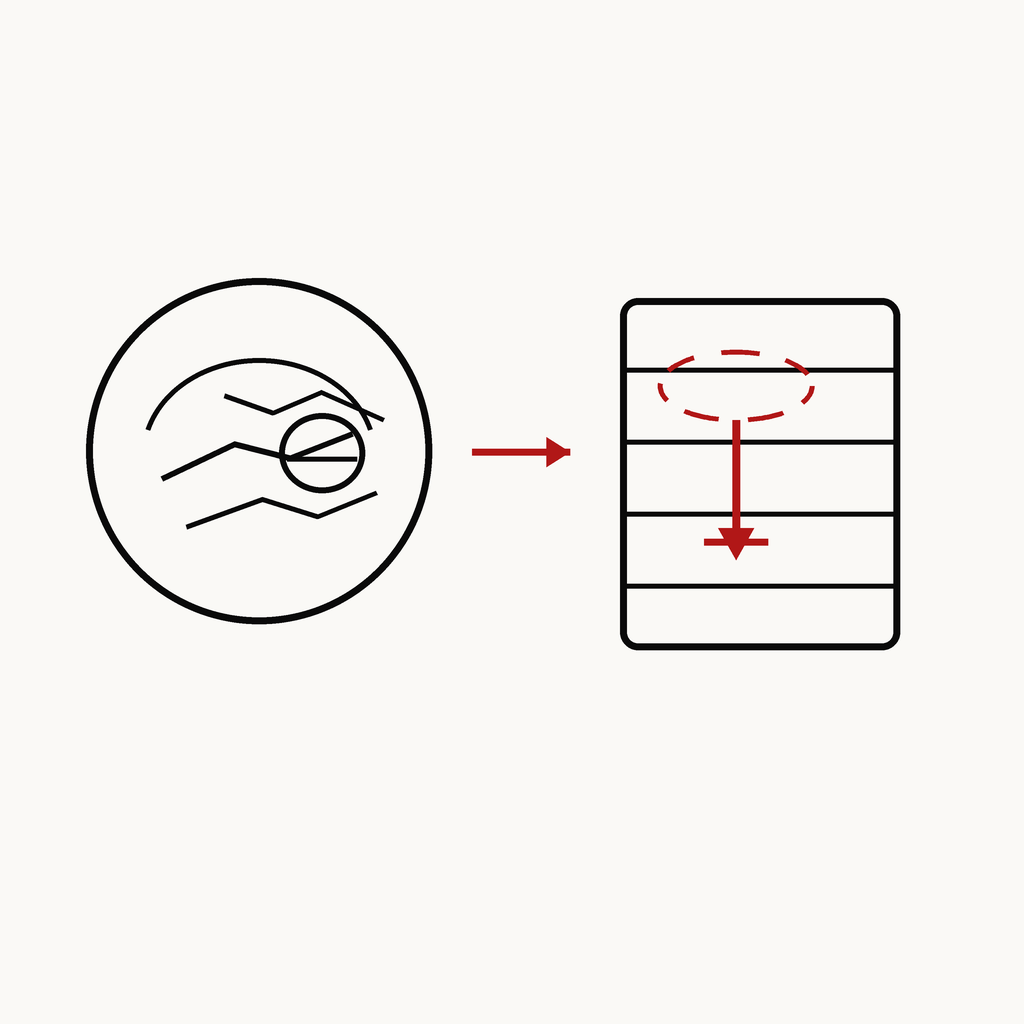
실시간 영상
Pathologic Outcome Prediction (EGC)
Gastric Cancer · 2024
① 내시경 영상 → 병리 결과 예측
② 인지 → 판단(추론) 파이프라인
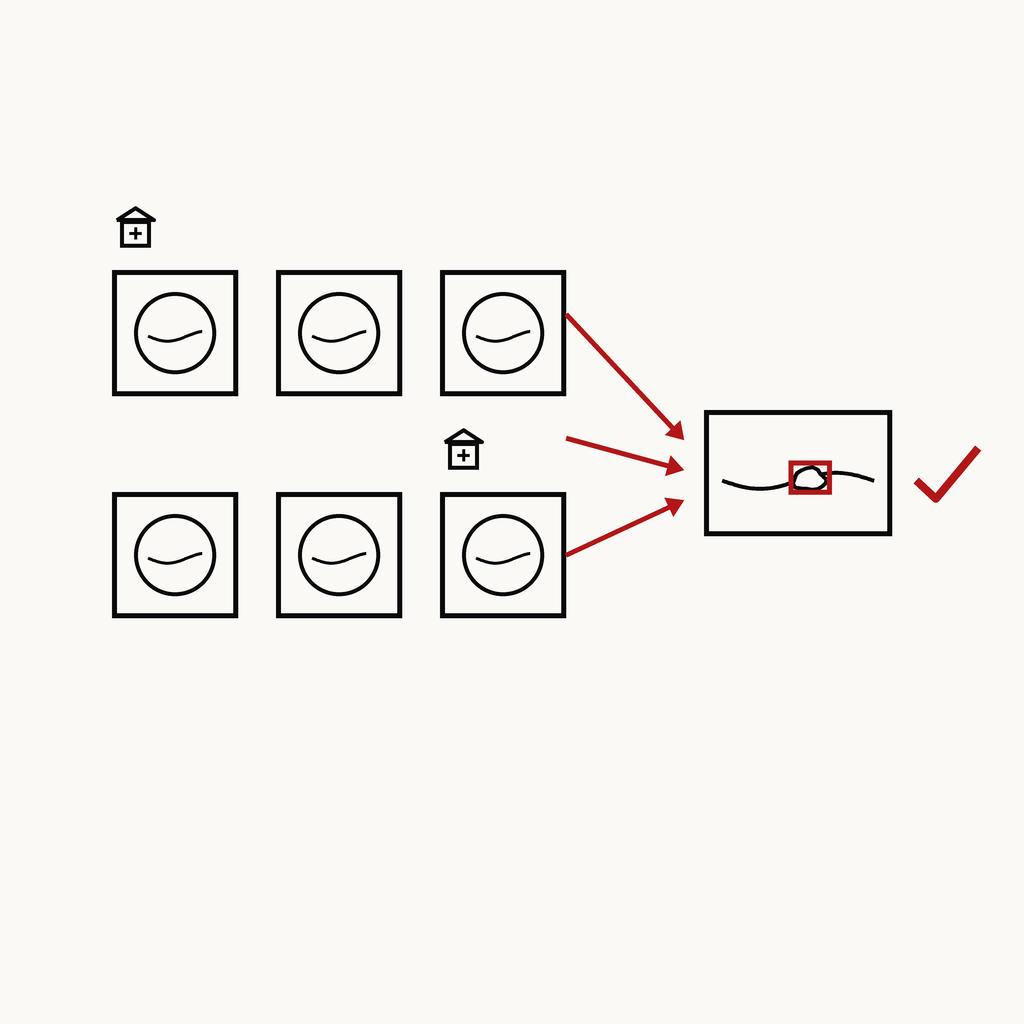
실시간 영상
Real-World Gastric Atypia / Neoplasm
J. Gastric Cancer · 2024
① 실제 임상환경 다기관 검출
② 벤치 점수 아닌 실배포 성능
foundations
Pragmatic Analog Network Coding (OFDM)
IEEE Trans. Wireless Comm. · 2014
① 다중중계 OFDM 신호처리 (석사)
② 시스템·신호 최적화 기반기
국내 · 엣지
DeepStream 다중 영상처리 객체검출 성능비교
한국통신학회(KICS) · 2021
① 엣지 다중스트림 객체검출 성능 비교
② 온디바이스 실시간 멀티스트림 = 게임 인지 예산
국내 · 국방
사전훈련 모델 기반 한국어 임베딩 성능 비교
한국국방기술학회 논문지 · 2020 (Vol.2)
① BERT 등 사전훈련 모델 파인튜닝 — 한국어 임베딩·감성분류 성능 비교
② 트랜스포머·전이학습 경험 — LLM·에이전트 기반 기술
16 / APPENDIX B — PATENTS · 실시간 영상 인지 (의료)
특허 ①축 — 실시간 영상으로 인지·판단 (등록 4 · 출원 2).
게임 에이전트의 실시간 화면 인지와 같은 결: 검출·분류·안정화·커버리지.
실시간 영상
폴립 검출 + 깜빡임 제거
KR102641489B1 · 등록
① 시간적 일관성으로 오탐·깜빡임 안정화
② 실시간 영상 인지의 정수 = 게임 에이전트
실시간 영상
내시경 영상 자동 인식·분석
KR102641492B1 · 등록
① 병변을 자동 인식·분석
② 실시간 인지 자동화
실시간 영상
내시경 영상분석 서비스
KR102841476B1 · 등록
① 검출+분류+품질평가+리포트 자동
② 인지 → 판단 → 산출 풀스택
실시간 영상
검사 커버리지 맵
KR102889999B1 · 등록
① 본/안 본 구역 실시간 색지도
② 실시간 커버리지 = 에이전트 상태추적

온디바이스
웨어러블 건강 모니터링
KR10-2024-0105250 · 출원
① 웨어러블로 개인 맞춤 건강 모니터링
② 온디바이스 실시간 센싱
실시간 영상
내시경 영상 AI 출원
KR10-2024-0053966 · 출원
① 내시경 영상 AI 관련 출원 (Ainex)
② 실시간 영상 인지 IP 확장
17 / APPENDIX B — PATENTS · 자율·시뮬레이션 (국방)
특허 ②축 — 인지한 뒤 자율로 판단·행동 (등록 3 · 출원 1).
시뮬레이터 객체생성(sim→real)은 KRAFTON 시뮬·Physical AI와 가장 직결되는 카드.
Sim→Real ★
시뮬레이터 객체 생성 (딥러닝)
KR20230072001A · 출원
① 실물 사진 → 자동 3D 시뮬 객체
② sim→real = KRAFTON Physical AI 직결
자율
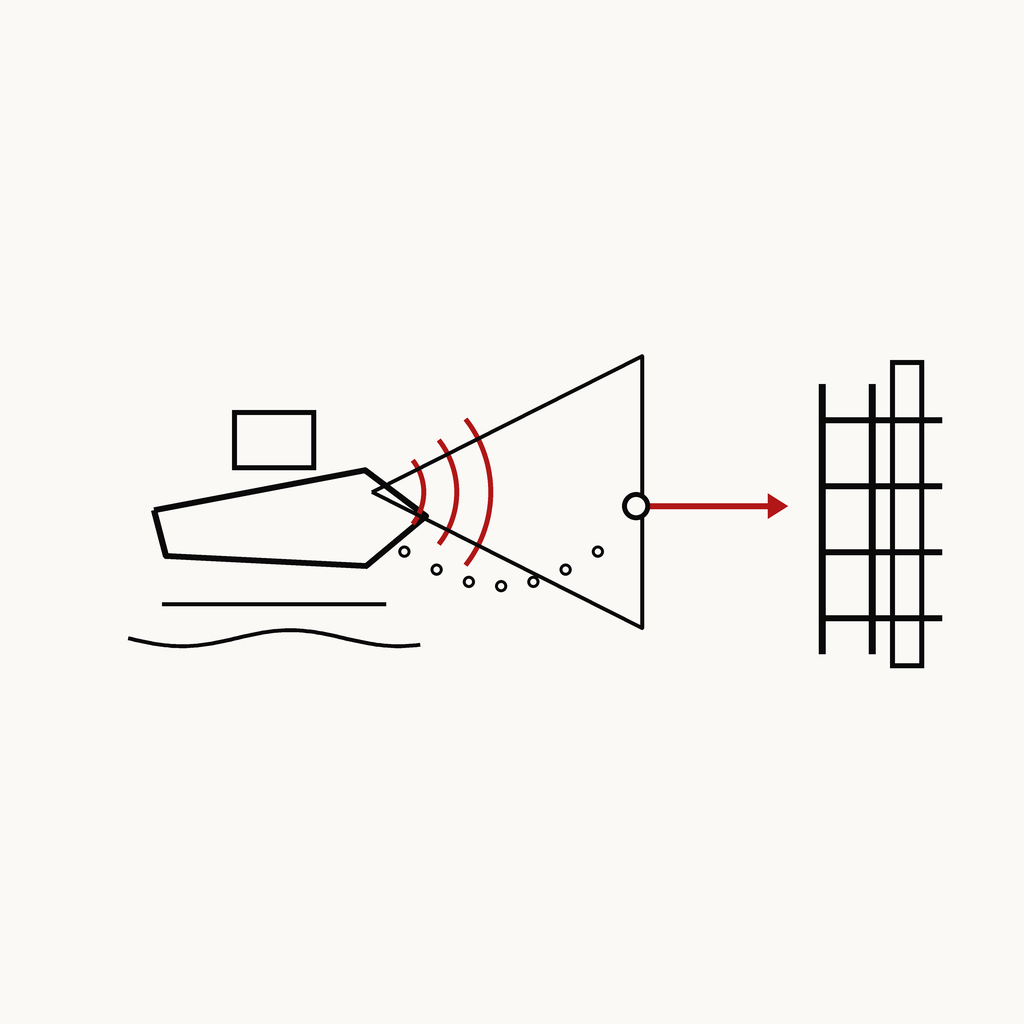
USV 자율 도킹 (센서퓨전)
KR102364611B1 · 등록
① 복합센서로 무인선 자동 접안
② 센서퓨전 + 실시간 제어 = 자율
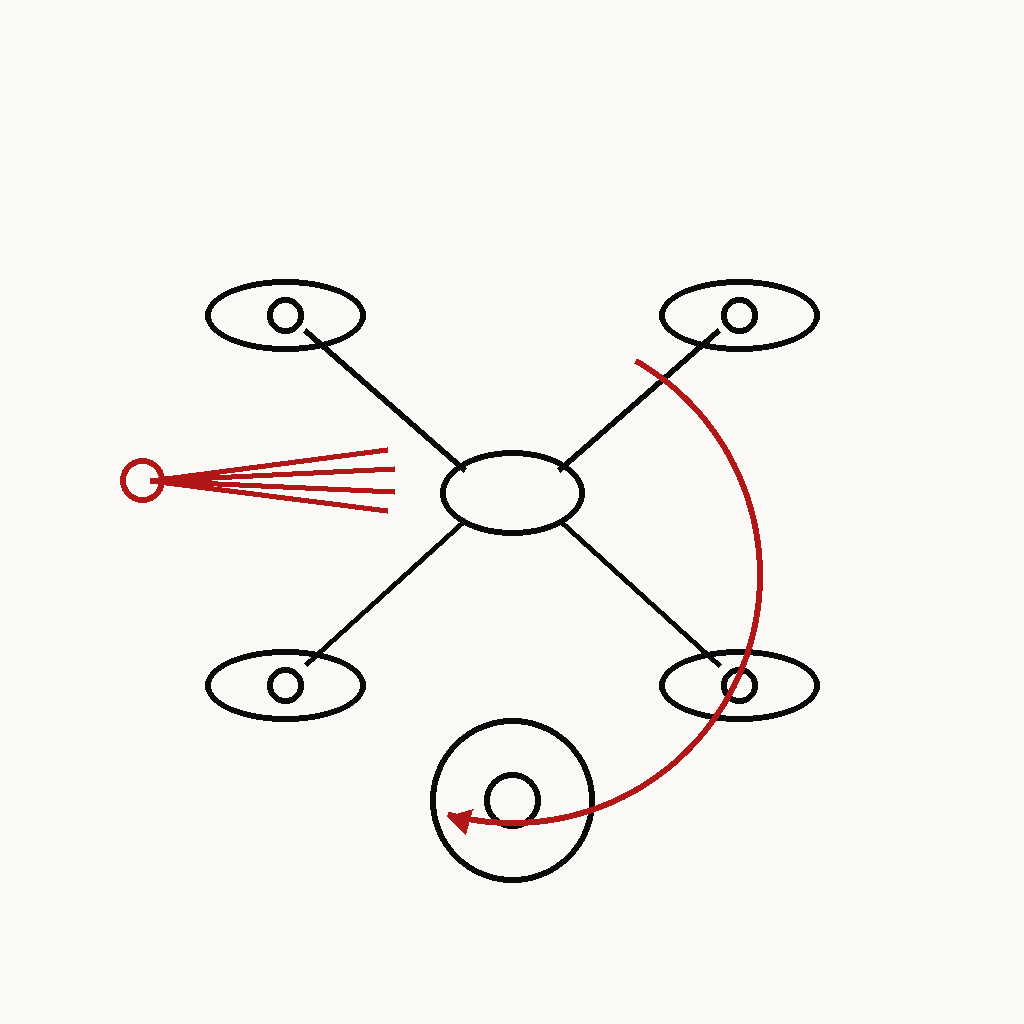
자율·보안
드론 안티해킹
KR102480380B1 · 등록
① 재밍·스푸핑 감지 → 자동 복귀
② 이상 감지 → 자율 행동(안전)
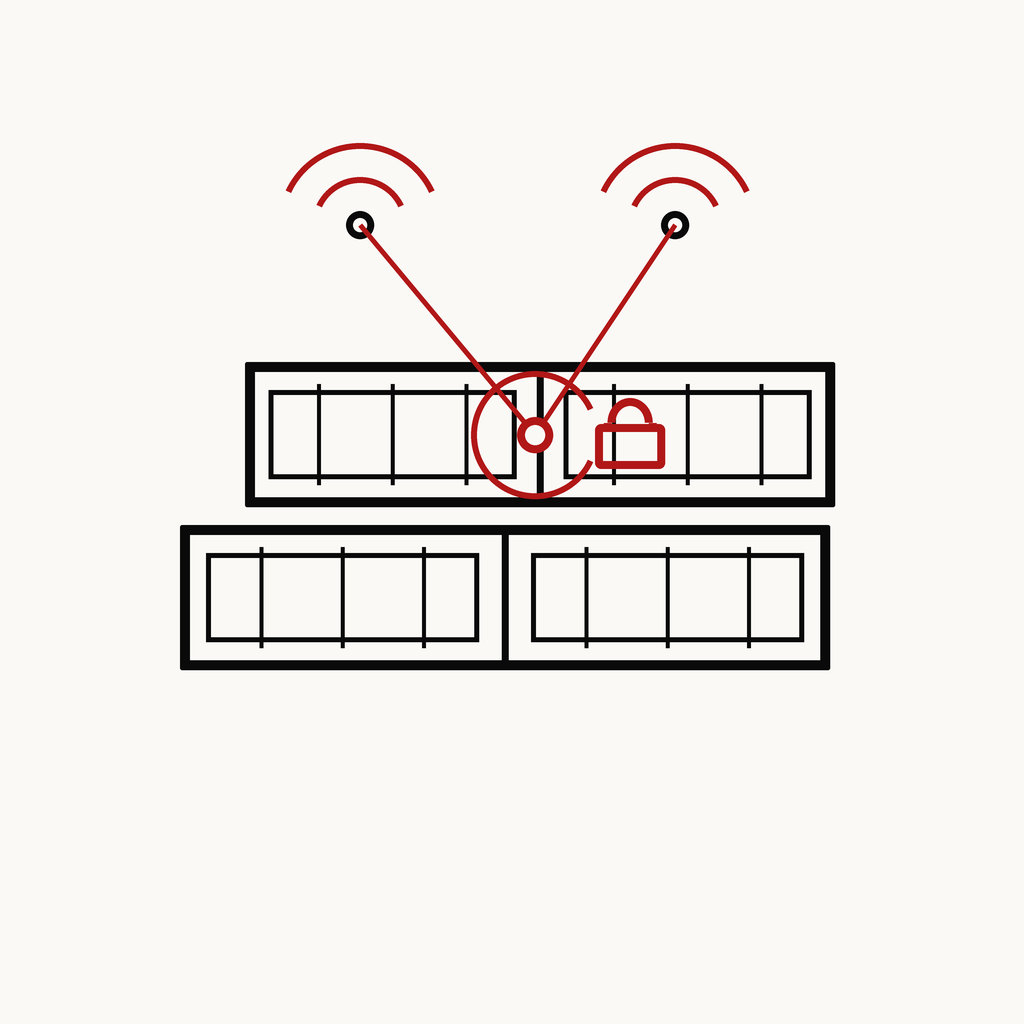
엣지 센싱
항만 컨테이너 보안 (UWB)
KR102562882B1 · 등록
① UWB 정밀위치 + 암호키 무열쇠 통제
② 저전력 엣지 센싱
한 줄 요약 — 두 축 모두 “실시간으로 인지하고 자율로 판단·행동”. 그래서 KRAFTON의 게임 에이전트·Physical AI와 같은 문제입니다.